Web-based Tools for Validating Image Segmentation of Concrete Samples
We facilitate visual validation of the following acquired SEM datasets:
We also included for validation the subsets of the above datasets that have been prepared as references for training supervised segmentation methods.
The preparation methods vary from manual annotations to algorithm-assisted where the algorithms include thresholding, contextual labeling, and rule-based mapping:
We facilitate visual validation of the AI models trained on the two reference datasets (damage-assisted and context-assisted):
The web visual validation system has been tested with Mozilla Firefox, Google Chrome and Safari browsers.
Approaches to prepare training segmented images:
Our approach is to prepare training image data in two ways:
- (1) 2D segmentation results assisted by contextual labels (rule-based model):
- First, intensity- and shape-based image segmentation of contextual labels is designed and optimized based on 12 pixel-level annotated FOVs. The contextual labels are color-encoded as follows:

- Next, rule-based model is designed to assign damage labels to damage sub-classes, such as paste damage, aggregate damage, and air voids.
The damage sub-class labels are color-encoded as follows:

- Finally, predicted damage sub-classes from contextual labels are visually verified and ranked for inclusion into a training set #1 as shown below.
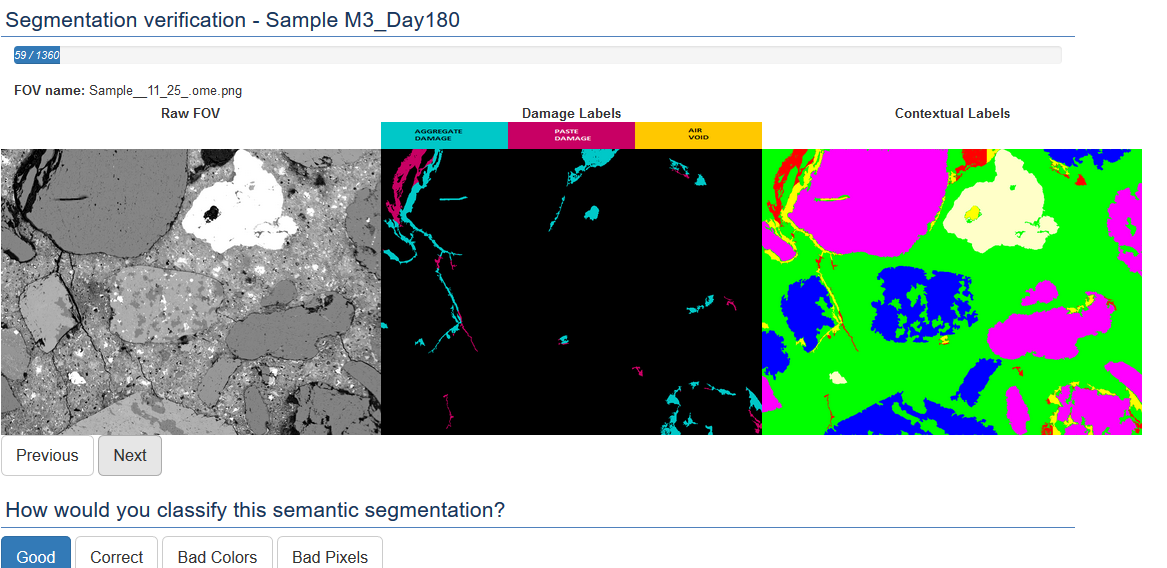
- (2) 2D segmentation results assisted by damage labels (U-Net and SegNet based models)
- First, binary segmentation into damage and no-damage classes is designed by assuming that all dark pixels belong to a damage class.
- Next, binary masks and raw FOVs are ovelaid in the web image processing pipeline (WIPP) system to facilitate manual annotations of the damage class into the damage sub-classes as illustrated below:

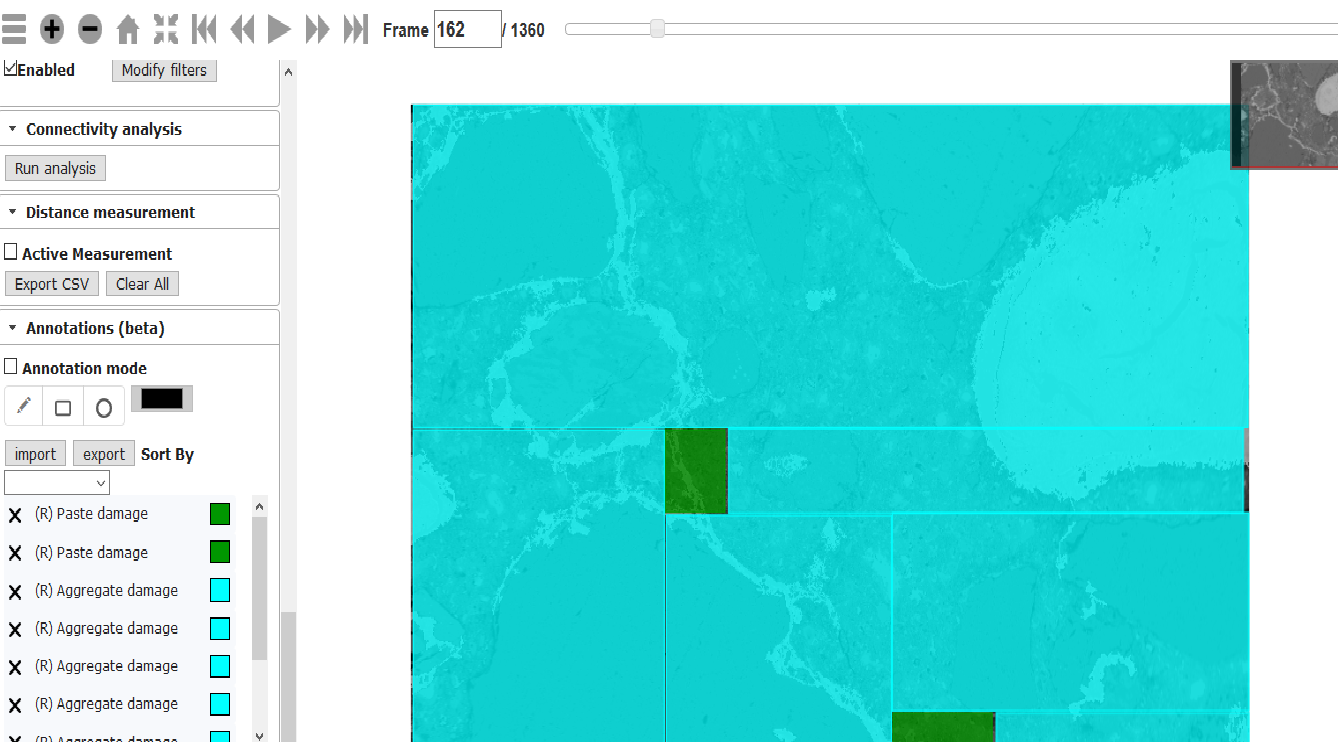
- Finally, the annotations are converted into multi-class masks and presented for visual validation before the amsks are included into a training set #2.
Both approaches to creating training image sets are executed in parallel and results are visually verified in order to assert trust in AI models.
Challenges:
The challenges lie in
- manually preparing 12 pixel-level annotated microscopy images with contextual classes for optimizing algorithmic parameters in steps (1) and (3),
- manually annotating 106 fields of views (FOVs) with bounding boxes and circles to denote three damage sub-classes,
- designing intensity- and shape-based image segmentation of contextual labels,
- visually verifying 1630 FOVs to prepare a large number of training images for AI model training.
Significance
Web-based visual validation system enables
- exploring very large numbers of images,
- engaging experts who are geographically distributed, and
- performing the visual validation consistently across multiple experts while imposing reasonable demands on inspection time.
Notation of Image Collections in Browser Tabs
The core sample nomenclature reflects:
- Large block number (1 of 4)
- Region within the block (level of rebar confinement)
- Position between Stirrups
- Direction Facing
- Height above base
- Age at coring
For example, the sample denoted as ‘1-1-S5-6-W-31-180d’ can be described as:
- Block 1 (low expansion mix)
- Region 1 (moderate confinement)
- Located between Stirrups 5-6
- West Facing
- Height 31 in.
- Age = 180 day
The sample location in the experimental setup can be inferred from the nomeclature as illustrated in the figure of concrete blocks below.

The prism sample nomenclature is related to the core nomenclature. For example, 3X-M3-P25_270d implies:
- 3X = 3x3 in cast prism
- M3 = High expansion Mix #3
- P25 = 25 °C equilibrated temperature
- 270d = sectioned after 270 days of reaction
The figure below shows the mapping betweeb the prism expansion data and keys to approximate sampling times for the Mix 3, 25 °C prisms:

